LXC 3.0.0 has been released¶
27 Mar 2018
Introduction¶
The LXC team is pleased to announce the release of LXC 3.0.0!
This is the result of over 6 months of intense work since the LXC 2.1.0 release
This is the third LTS release for the LXC project and will be supported until June 2023.
Major changes¶
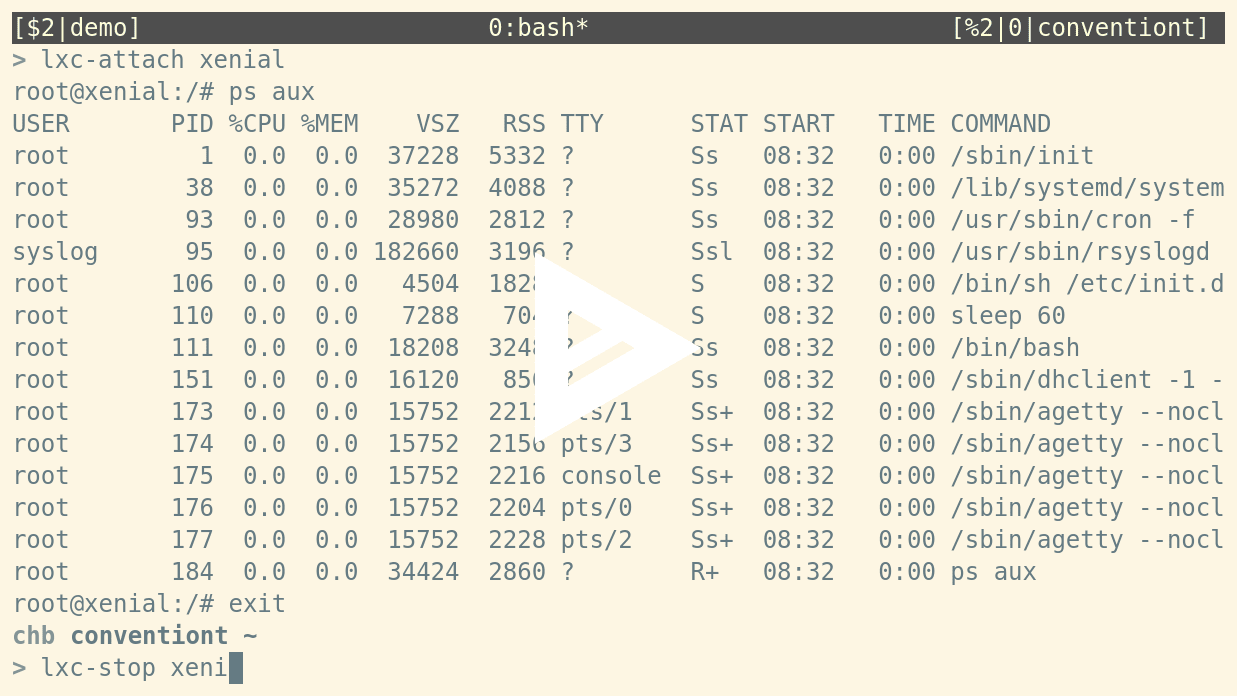
All commands support lxc-start <container-name> syntax¶
The LXC tools now support passing the container name without the -n command line flag. For example, you can now run:
chb@conventiont|~
> lxc-start xenial
chb@conventiont|~
> lxc-info xenial
Name: xenial
State: RUNNING
PID: 12765
Memory use: 15.24 MiB
KMem use: 3.72 MiB
Link: veth99VMO3
TX bytes: 858 bytes
RX bytes: 2.49 KiB
Total bytes: 3.33 KiB
chb@conventiont|~
> lxc-attach xenial
root@xenial:/# exit
chb@conventiont|~
> lxc-stop xenial
Removed support for all legacy configuration keys¶
All legacy configuration keys are unsupported from LXC 3.0 onwards.
The full list of deprecated keys and their new counterparts can be gathered from the LXC 2.1 release announcement.
The lxc-update-config tool can be used to convert an older, now invalid, configuration to the new format.
Full support for the unified cgroup hierarchy including resource limits¶
We are pleased to announce that LXC will fully support the new unified cgroup hierarchy (or cgroup v2, cgroup2). To this end we also introduced a new configuration key lxc.cgroup2.[controller name] to configure cgroup limits on the unified cgroup hierarchy.
For detailed information you can read this blogpost.
Removal of legacy cgmanager and cgfs cgroup drivers¶
LXC removed the cgmanager and cgfs legacy cgroup drivers cleaning up a lot of code in the process. For detailed information you can read this blogpost.
Splitting out templates and language bindings¶
LXC removes the legacy template-based container build system in favor of the new project distrobuilder. For detailed information you can read this blogpost.
Note that to simplify migration, the old template scripts and configuration files remain available in a separate repository and are released along with LXC 3.0.0 as lxc-templates.
The following templates remain in the LXC 3.0 tree and are fully supported:
- lxc-busybox (mostly used for testing)
This is a very minimal template which can be used to setup a busybox container. As long as the busybox binary is found you can always built yourself a very minimal privileged or unprivileged system or application container image; no networking or any other dependencies required. All you need to do is:
lxc-create c3 -t busybox
[<img src='https://discuss.linuxcontainers.org/uploads/default/original/1X/3719f8fe09f03069e3741d1ba64141f3d9540b54.png' alt='asciicast'>](https://asciinema.org/a/165788)
- lxc-download (download our pre-built images)
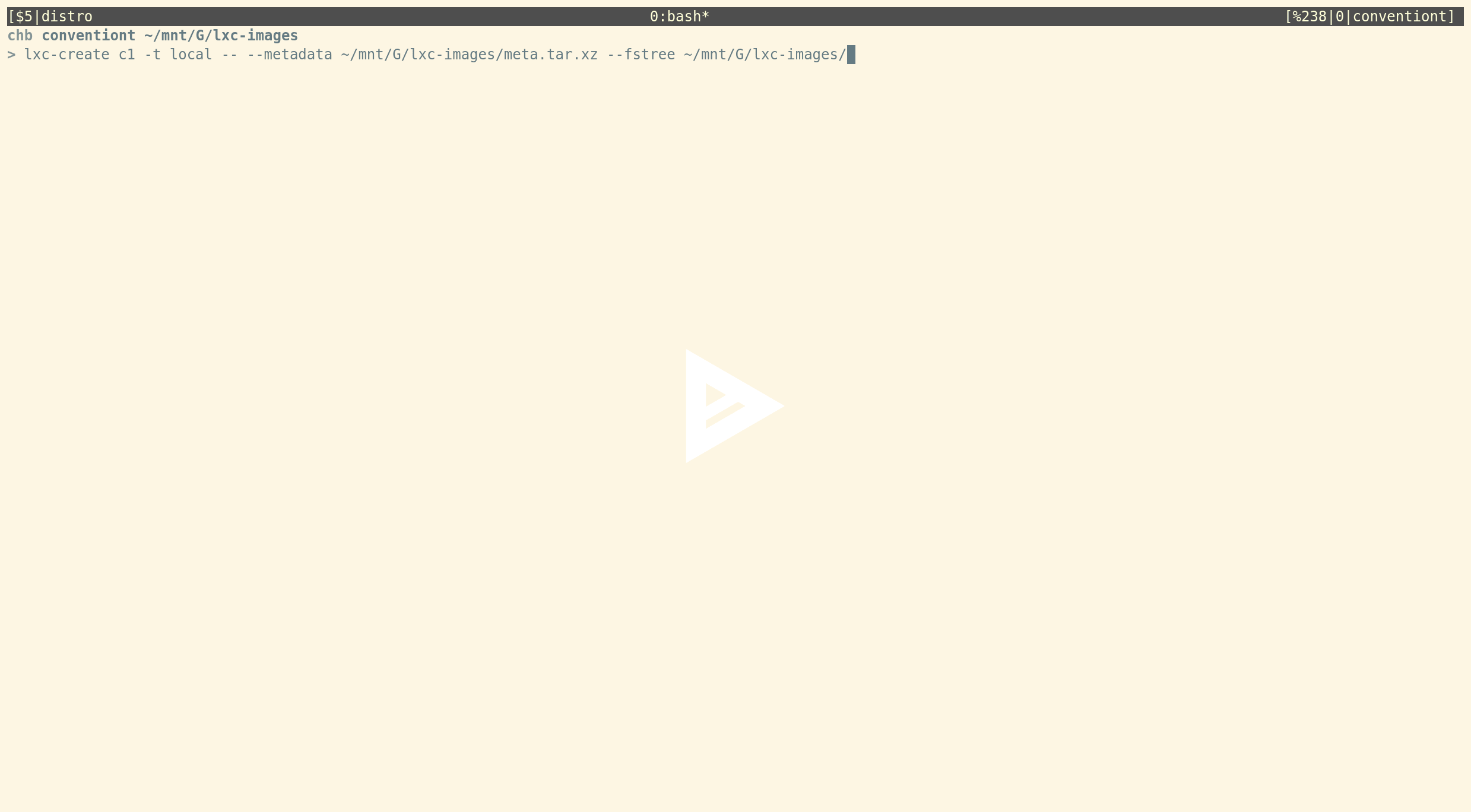
This template lets you download pre-built images from our image servers. This is likely what currently most users are using to create unprivileged containers. - lxc-local (import locally build images (e.g. from distrobuilder))
This is a new template which consumes standardLXCandLXDsystem container images. A container can be created with:
lxc-create c1 -t local -- --metadata /path/to/meta.tar.xz --fstree /path/to/rootfs.tar.xz
where the --metadata flag needs to point to a file containing the metadata for the container. This is simply the standard meta.tar.xz file that comes with any pre-built LXC container image. The --fstree flag needs to point to a filesystem tree. Creating a container is then just:
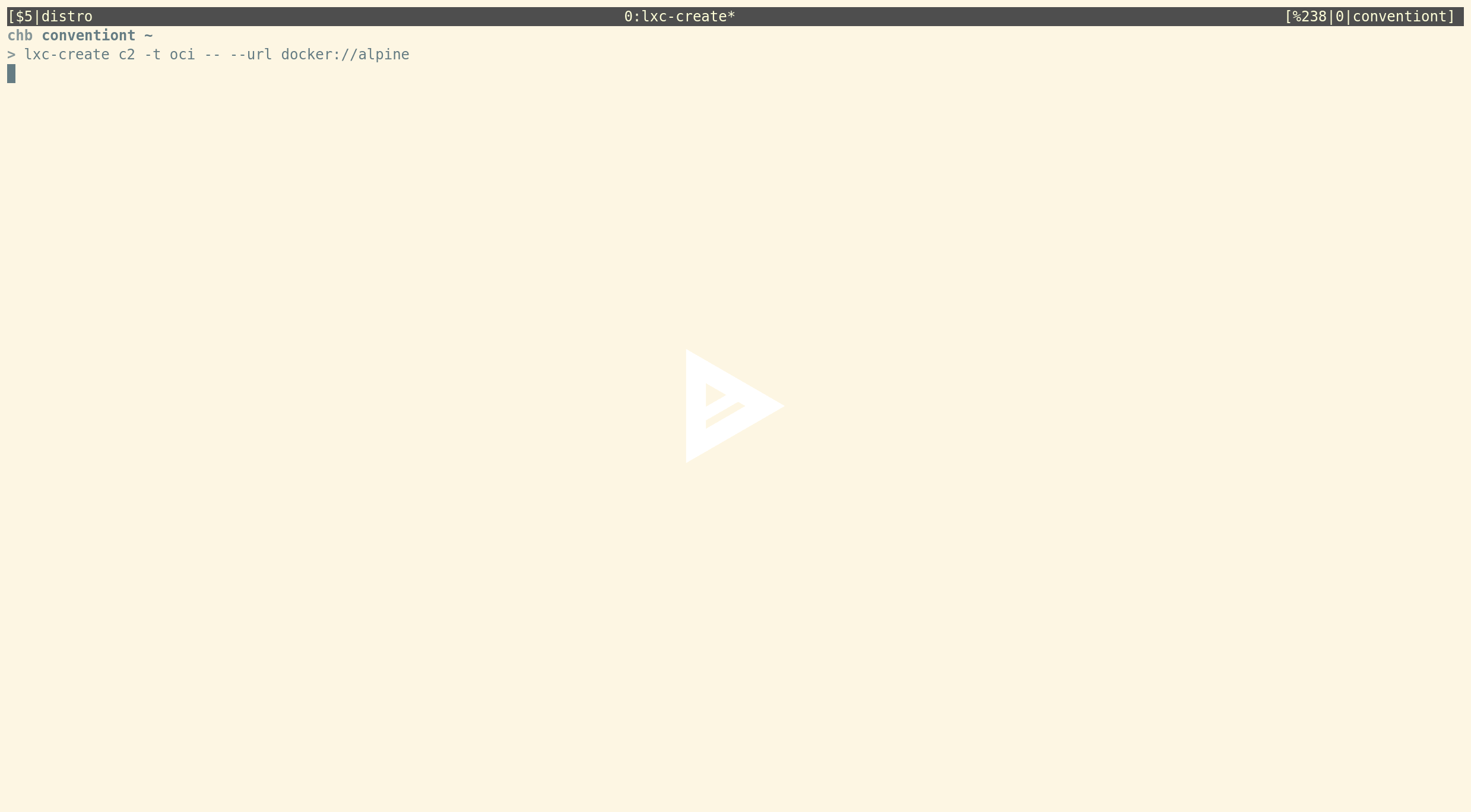
- lxc-oci (use OCI application container images)
This is the template which can be used to download and run OCI containers. Using it is as simple as:
lxc-create c2 -t oci -- --url docker://alpine
Here's another asciicast:
Moving the cgroup PAM module into the LXC tree¶
LXC has always supported fully unprivileged containers, i.e. unprivileged containers run by unprivileged users. An important piece in doing so was a PAM module that created writable cgroups for unprivileged users. This has been moved from the LXCFS tree into the LXC tree itself to make it even easier for users to run fully unprivileged containers.
For detailed information you can read this blogpost.
New OCI template¶
This adds support for creating application containers from OCI formats.
Examples:
- create a container from a local OCI layout in ../oci:
sudo lxc-create -t oci -n a1 -- -u oci:../oci:alpine
- create a container pulling from the docker hub.
sudo lxc-create -t oci -n u1 -- -u docker://ubuntu
The URL is specified in the same format as for skopeo copy.
Simple and efficient ringbuffer for console logging¶
LXC supports logging the container's console to a file. This had the unfortunate side effect of allowing a user in the container to effectively write as much data as they wanted on the host, possibly bypassing quotas in place for the container.
This basic implementation was also somewhat annoying to query, having to read a potentially huge file which wasn't reset on container restart.
LXC 3.0 now introduces a ringbuffer for console logging. This in-memory buffer is size-limited and can be queried through a new function in the LXC API. It can be reset at any time and can be dumped to disk on container shutdown.
Allow seccomp to filter syscalls based on arguments¶
In order to support filtering syscalls based on arguments the seccomp version 2 specification is extended to the following form:
syscall_name action [index,value,op,valueTwo] [index,value,op]...
where the arguments of the tuple [index,value,valueTwo,op] have the following meaning:
- index (
uint32_t):
The index of the syscall argument. - value (
uint64_t):
The value for the syscall argument specified by "index". - valueTwo (
uint64_t, optional):
The value for the syscall argument specified by "index". This optional value
is only valid in conjunction withSCMP_CMP_MASKED_EQ. -
op (
char *):
The operator for the syscall argument. Valid operators are the constantsSCMP_CMP_NEor(!=)SCMP_CMP_LEor(<=)SCMP_CMP_EQor(==)SCMP_CMP_GEor(>=)SCMP_CMP_GTor(>)SCMP_CMP_MASKED_EQor(&=)
as defined by
libseccomp >= v2.3.2.
For convenience liblxc also understands the standard operator notation indicated in brackets after the libseccomp constants above as an equivalent notation.
Note that it is legal to specify multiple entries for the same syscall.
An example for an extended seccomp version 2 profile is:
2
blacklist allow
reject_force_umount # comment this to allow umount -f; not recommended
[all]
kexec_load errno 1 [0,1,SCMP_CMP_LE][3,1,==][5,1,SCMP_CMP_MASKED_EQ,1]
open_by_handle_at errno 1
init_module errno 1
finit_module errno 1
delete_module errno 1
unshare errno 9 [0,0x10000000,SCMP_CMP_EQ]
unshare errno 2 [0,0x20000000,SCMP_CMP_EQ]
Support for daemonized app containers¶
LXC has been running application container through a minimal init system since its first release in 2008. PID namespaces expect a functional init system capable of handling signals and reaping exiting child processes. This is why application containers always run the application as the second process.
New versions of LXC will now additionally allow you to run basically any process daemonized:
Remove all internal symbols from lxc-* tools¶
The lxc-* tools now only entirely rely on the public LXC API.
Handle /proc being mounted with the hidepid={1,2} property¶
This enables attaching to containers when the host's /proc filesystem was mounted with the hidepid={1,2} option which restricts access to /proc/PID directories.
Support mount propagation for mounts¶
This adds support for mount propagation (private, shared, slave, unbindable, rprivate, rshared, rslave, runbindable) to mount entries specified via lxc.mount.entry and lxc.mount.fstab.
Hardened thread-safety¶
- removed all mutexes
- replaced all calls to
exit()in child processes with_exit() - replaced all
F_SETLK,F_SETLKW,F_GETLKwithF_OFD_SETLK,F_OFD_SETLKW,F_OFD_GETLKopen file description locks
If open file descriptions locks are not available LXC will fallback to BSDflock()s.
More details can be gathered from this blogpost.
Remove aufs storage driver¶
The aufs storage driver has been deprecated since LXC 2.1 and is now officially removed.
Coding style and code cleanups¶
Code cleanups have been performed widely across the codebase based on our written down coding style.
New Configuration Keys¶
lxc.cgroup2.[controller name]¶
Specify the control group value to be set on the unified cgroup shierarchy. The controller name is the literal name of the control group. The permitted names and the syntax of their values is not dictated by LXC, instead it depends on the features of the Linux kernel running at the time the container is started, for example, lxc.cgroup2.memory.high.
lxc.hook.version¶
To pass the arguments in new style via environment variables set to 1 otherwise set to 0 to pass them as arguments. This setting affects all hooks arguments that were traditionally passed as arguments to the script. Specifically, it affects the container name, section (e.g. 'lxc', 'net') and hook type (e.g. 'clone', 'mount', 'pre-mount') arguments. If new-style hooks are used then the arguments will be available as environment variables. The container name will be set in LXC_NAME. (This is set independently of the value used for this config item.) The section will be set LXC_HOOK_SECTION and the hook type will be set in LXC_HOOK_TYPE. It also affects how the paths to file descriptors referring to the container's namespaces are passed. If set to 1 then for each namespace a separate environment variable LXC_[NAMESPACE IDENTIFIER]_NS will be set. If set to 0 then the paths will be passed as arguments to the stop hook.
lxc.execute.cmd¶
Absolute path from container rootfs to the binary to run by default. This configuration options can be set to to specify the default binary for application container started via the execute() API call and accompanies the system container based lxc.init.cmd configuration key.
lxc.init.cwd¶
Absolute path inside the container to use as the working directory.
lxc.proc.[proc file name]¶
Specify the proc file name to be set. The file names available are those listed under the /proc/PID/ directory. For example, lxc.proc.oom_score_adj = 10.
lxc.console.buffer.size¶
Setting this option instructs LXC to allocate an in-memory ringbuffer. The container's console output will be written to the ringbuffer. Note that ringbuffer must be at least as big as a standard page size. When passed a value smaller than a single page size LXC will allocate a ringbuffer of a single page size. A page size is usually 4kB. The keyword auto will cause LXC to allocate a ringbuffer of 128kB. When manually specifying a size for the ringbuffer the value should be a power of 2 when converted to bytes. Valid size prefixes are kB, MB, GB. (Note that all conversions are based on multiples of 1024. That means kb == KiB, MB == MiB, GB == GiB.)
lxc.console.size¶
Setting this option instructs LXC to place a limit on the size of the console log file specified in lxc.console.logfile. Note that size of the log file must be at least as big as a standard page size. When passed a value smaller than a single page size LXC will set the size of log file to a single page size. A page size is usually 4kB. The keyword auto will cause LXC to place a limit of 128kB on the log file. When manually specifying a size for the log file the value should be a power of 2 when converted to bytes. Valid size prefixes are kB, MB, GB. (Note that all conversions are based on multiples of 1024. That means kb == KiB, MB == MiB, GB == GiB.) If users want to mirror the console ringbuffer on disk they should set lxc.console.size equal to lxc.console.buffer.size.
lxc.console.rotate¶
Whether to rotate the console logfile specified in lxc.console.logfile.
relative option for lxc.mount.entry¶
A mountpoint specified with the relative property set will be taken to be relative to the mounted container root. For instance,
lxc.mount.entry = /dev/null proc/kcore none bind,relative 0 0
Will expand dev/null to ${LXC_ROOTFS_MOUNT}/dev/null, and mount it to proc/kcore inside the container.
force property for cgroup mounts specified via lxc.mount.auto¶
cgroup:mixed:force:¶
The force option will cause LXC to perform the cgroup mounts for the container under all circumstances. Otherwise it is similar to cgroup:mixed. This is mainly useful when the cgroup namespaces are enabled where LXC will normally leave mounting cgroups to the init binary of the container since it is perfectly safe to do so.
cgroup:ro:force:¶
The force option will cause LXC to perform the cgroup mounts for the container under all circumstances. Otherwise it is similar to cgroup:ro. This is mainly useful when the cgroup namespaces are enabled where LXC will normally leave mounting cgroups to the init binary of the container since it is perfectly safe to do so.
cgroup:rw:force:¶
The force option will cause LXC to perform the cgroup mounts for the container under all circumstances. Otherwise it is similar to cgroup:rw. This is mainly useful when the cgroup namespaces are enabled where LXC will normally leave mounting cgroups to the init binary of the container since it is perfectly safe to do so.
cgroup-full:mixed:force:¶
The force option will cause LXC to perform the cgroup mounts for the container under all circumstances. Otherwise it is similar to cgroup-full:mixed. This is mainly useful when the cgroup namespaces are enabled where LXC will normally leave mounting cgroups to the init binary of the container since it is perfectly safe to do so.
cgroup-full:ro:force:¶
The force option will cause LXC to perform the cgroup mounts for the container under all circumstances. Otherwise it is similar to cgroup-full:ro. This is mainly useful when the cgroup namespaces are enabled where LXC will normally leave mounting cgroups to the init binary of the container since it is perfectly safe to do so.
cgroup-full:rw:force:¶
The force option will cause LXC to perform the cgroup mounts for the container under all circumstances. Otherwise it is similar to cgroup-full:rw. This is mainly useful when the cgroup namespaces are enabled where LXC will normally leave mounting cgroups to the init binary of the container since it is perfectly safe to do so.
lxc.namespace.clone¶
Specify namespaces which the container is supposed to be created with. The namespaces to create are specified as a space separated list. Each namespace must correspond to one of the standard namespace identifiers as seen in the /proc/PID/ns directory. When lxc.namespace.clone is not explicitly set all namespaces supported by the kernel and the current configuration will be used.
To create a new mount, net and ipc namespace set lxc.namespace.clone = mount net ipc.
lxc.namespace.keep¶
Specify namespaces which the container is supposed to inherit from the process that created it. The namespaces to keep are specified as a space separated list. Each namespace must correspond to one of the standard namespace identifiers as seen in the /proc/PID/ns directory. The lxc.namespace.keep is a blacklist option, i.e. it is useful when enforcing that containers must keep a specific set of namespaces.
To keep the network, user and ipc namespace set lxc.namespace.keep = user net ipc.
Note that sharing pid namespaces will likely not work with most init systems.
Note that if the container requests a new user namespace and the container wants to inherit the network namespace it needs to inherit the user namespace as well.
lxc.namespace.share.[namespace identifier]¶
Specify a namespace to inherit from another container or process. The [namespace identifier] suffix needs to be replaced with one of the namespaces that appear in the /proc/PID/ns directory.
To inherit the namespace from another process set the lxc.namespace.share.[namespace identifier] to the PID of the process, e.g. lxc.namespace.share.net = 42.
To inherit the namespace from another container set the lxc.namespace.share.[namespace identifier] to the name of the container, e.g. lxc.namespace.share.pid = c3.
To inherit the namespace from another container located in a different path than the standard LXC path set the lxc.namespace.share.[namespace identifier] to the full path to the container, e.g. lxc.namespace.share.user = /opt/c3.
In order to inherit namespaces the caller needs to have sufficient privilege over the process or container.
Note that sharing pid namespaces between system containers will likely not work with most init systems.
Note that if two processes are in different user namespaces and one process wants to inherit the other's network namespace it usually needs to inherit the user namespace as well.
lxc.sysctl.[kernel parameters name]¶
Specify the kernel parameters to be set. The parameters available are those listed under /proc/sys/. Note that not all sysctls are namespaced. Changing Non-namespaced sysctls will cause the system-wide setting to be modified. sysctl(8). If used with no value, LXC will clear the parameters specified up to this point.
lxc.hook.start-host¶
A hook to be run in the host's namespace after the container has been setup, and immediately before starting the container init.
This should satisfy several use cases. One example is support for CNI.
For example, replace the network configuration in a root owned container with:
lxc.net.0.type = empty
lxc.hook.start-host = /bin/lxc-start-netns
where /bin/lxc-start-netns contains:
=================================
echo "starting" > /tmp/debug
ip link add host1 type veth peer name peer1
ip link set host1 master lxcbr0
ip link set host1 up
ip link set peer1 netns "${LXC_PID}"
=================================
The nic 'peer1' was placed into the container as expected.
For this to work, we pass the container init's pid as LXC_PID in an environment variable, since lxc-info cannot work at that point.
API extensions¶
console_log()¶
A new API extension
int console_log(struct lxc_container *c, struct lxc_console_log *log);
has been added that supports interacting with the newly added in-memory ringbuffer of the container. The following struct contains available arguments and return values:
struct lxc_console_log {
/* Clear the console log. */
bool clear;
/* Retrieve the console log. */
bool read;
/* This specifies the maximum size to read from the ringbuffer. Setting
* it to 0 means that the a read can be as big as the whole ringbuffer.
* On return callers can check how many bytes were actually read.
* If "read" and "clear" are set to false and a non-zero value is
* specified then up to "read_max" bytes of data will be discarded from
* the ringbuffer.
*/
uint64_t *read_max;
/* Data that was read from the ringbuffer. If "read_max" is 0 on return
* "data" is invalid.
*/
char *data;
};
reboot2()¶
This adds reboot2() as a new API extension. This function properly wait until a reboot succeeded. It takes a timeout argument. When set to > 0 reboot2() will block until the timeout is reached, if timeout is set to zero reboot2() will not block, if set to -1 reboot2() will block indefinitely.
MIGRATE_FEATURE_CHECK for CRIU `migrate() API call¶
For migration optimization features like pre-copy or post-copy migration the support cannot be determined by simply looking at the CRIU version. Features like that depend on the architecture/kernel/criu combination and CRIU offers a feature checking interface to query if it is supported.
This adds a LXC interface to query CRIU for those feature via the migrate() API call. For the recent pre-copy migration support in LXD this can be used to automatically detect if pre-copy migration should be used.
In addition to the existing migrate() API commands this adds a new command: MIGRATE_FEATURE_CHECK.
The struct migrate_opts is extended by the member features_to_check which is a bitmask defining which CRIU features should be queried.
Currently only querying the features FEATURE_MEM_TRACK and FEATURE_LAZY_PAGES are supported.
add LXC_ATTACH_TERMINAL to attach() API call¶
Allocation of a new terminal has been moved into the API itself. Callers can now set LXC_ATTACH_TERMINAL to request to be attached to a new terminal allocated from the host's devpts mount before attaching to the container.
Support and upgrade¶
LXC 3.0.0 will be supported until June 2023 and our current LTS release.
LXC 2.0 will now join LXC 1.0 in only getting critical bugfixes and security updates.
We strongly recommend all LXC users to plan an upgrade to the 3.0 branch.
Due to the transition of libpam-cgfs to LXC, this should be done at the same time as the upgrade to LXCFS 3.0 to avoid potential conflicts.
Downloads¶
- LXC release tarball: lxc-3.0.0.tar.gz (GPG: lxc-3.0.0.tar.gz.asc)
- LXC templates tarball: lxc-templates-3.0.0.tar.gz (GPG: lxc-templates-3.0.0.tar.gz.asc)
- LXC python3 bindings tarball: python3-lxc-3.0.1.tar.gz (GPG: python3-lxc-3.0.1.tar.gz.asc)
Contributors¶
The LXC 3.0.0 release was brought to you by a total of 42 contributors.