How to monitor metrics¶
Incus collects metrics for all running instances as well as some internal metrics. These metrics cover the CPU, memory, network, disk and process usage. They are meant to be consumed by Prometheus, and you can use Grafana to display the metrics as graphs. See Provided metrics for lists of available metrics.
In a cluster environment, Incus returns only the values for instances running on the server that is being accessed. Therefore, you must scrape each cluster member separately.
The instance metrics are updated when calling the /1.0/metrics endpoint.
To handle multiple scrapers, they are cached for 8 seconds.
Fetching metrics is a relatively expensive operation for Incus to perform, so if the impact is too high, consider scraping at a higher than default interval.
Query the raw data¶
To view the raw data that Incus collects, use the incus query command to query the /1.0/metrics endpoint:
~$ incus query /1.0/metrics# HELP incus_cpu_seconds_total The total number of CPU time used in seconds.# TYPE incus_cpu_seconds_total counterincus_cpu_seconds_total{cpu="0",mode="system",name="u1",project="default",type="container"} 60.304517incus_cpu_seconds_total{cpu="0",mode="user",name="u1",project="default",type="container"} 145.647502incus_cpu_seconds_total{cpu="0",mode="iowait",name="vm",project="default",type="virtual-machine"} 4614.78incus_cpu_seconds_total{cpu="0",mode="irq",name="vm",project="default",type="virtual-machine"} 0incus_cpu_seconds_total{cpu="0",mode="idle",name="vm",project="default",type="virtual-machine"} 412762incus_cpu_seconds_total{cpu="0",mode="nice",name="vm",project="default",type="virtual-machine"} 35.06incus_cpu_seconds_total{cpu="0",mode="softirq",name="vm",project="default",type="virtual-machine"} 2.41incus_cpu_seconds_total{cpu="0",mode="steal",name="vm",project="default",type="virtual-machine"} 9.84incus_cpu_seconds_total{cpu="0",mode="system",name="vm",project="default",type="virtual-machine"} 340.84incus_cpu_seconds_total{cpu="0",mode="user",name="vm",project="default",type="virtual-machine"} 261.25# HELP incus_cpu_effective_total The total number of effective CPUs.# TYPE incus_cpu_effective_total gaugeincus_cpu_effective_total{name="u1",project="default",type="container"} 4incus_cpu_effective_total{name="vm",project="default",type="virtual-machine"} 0# HELP incus_disk_read_bytes_total The total number of bytes read.# TYPE incus_disk_read_bytes_total counterincus_disk_read_bytes_total{device="loop5",name="u1",project="default",type="container"} 2048incus_disk_read_bytes_total{device="loop3",name="vm",project="default",type="virtual-machine"} 353280...Set up Prometheus¶
To gather and store the raw metrics, you should set up Prometheus. You can then configure it to scrape the metrics through the metrics API endpoint.
Expose the metrics endpoint¶
To expose the /1.0/metrics API endpoint, you must set the address on which it should be available.
To do so, you can set either the core.metrics_address server configuration option or the core.https_address server configuration option.
The core.metrics_address option is intended for metrics only, while the core.https_address option exposes the full API.
So if you want to use a different address for the metrics API than for the full API, or if you want to expose only the metrics endpoint but not the full API, you should set the core.metrics_address option.
For example, to expose the full API on the 8443 port, enter the following command:
incus config set core.https_address ":8443"
To expose only the metrics API endpoint on the 8444 port, enter the following command:
incus config set core.metrics_address ":8444"
To expose only the metrics API endpoint on a specific IP address and port, enter a command similar to the following:
incus config set core.metrics_address "192.0.2.101:8444"
Add a metrics certificate to Incus¶
Authentication for the /1.0/metrics API endpoint is done through a metrics certificate.
A metrics certificate (type metrics) is different from a client certificate (type client) in that it is meant for metrics only and doesn’t work for interaction with instances or any other Incus entities.
To create a certificate, enter the following command:
openssl req -x509 -newkey ec -pkeyopt ec_paramgen_curve:secp384r1 -sha384 -keyout metrics.key -nodes -out metrics.crt -days 3650 -subj "/CN=metrics.local"
Note
The command requires OpenSSL version 1.1.0 or later.
Then add this certificate to the list of trusted clients, specifying the type as metrics:
incus config trust add-certificate metrics.crt --type=metrics
If requiring TLS client authentication isn’t possible in your environment, the /1.0/metrics API endpoint can be made available to unauthenticated clients.
While not recommended, this might be acceptable if you have other controls in place to restrict who can reach that API endpoint. To disable the authentication on the metrics API:
# Disable authentication (NOT RECOMMENDED)
incus config set core.metrics_authentication false
Make the metrics certificate available for Prometheus¶
If you run Prometheus on a different machine than your Incus server, you must copy the required certificates to the Prometheus machine:
The metrics certificate (
metrics.crt) and key (metrics.key) that you createdThe Incus server certificate (
server.crt) located in/var/lib/incus/
Copy these files into a tls directory that is accessible to Prometheus, for example, /etc/prometheus/tls.
See the following example commands:
# Create tls directory
mkdir /etc/prometheus/tls/
# Copy newly created certificate and key to tls directory
cp metrics.crt metrics.key /etc/prometheus/tls/
# Copy Incus server certificate to tls directory
cp /var/lib/incus/server.crt /etc/prometheus/tls/
# Make the files accessible by prometheus
chown -R prometheus:prometheus /etc/prometheus/tls
Configure Prometheus to scrape from Incus¶
Finally, you must add Incus as a target to the Prometheus configuration.
To do so, edit /etc/prometheus/prometheus.yaml and add a job for Incus.
Here’s what the configuration needs to look like:
global:
# How frequently to scrape targets by default. The Prometheus default value is 1m.
scrape_interval: 15s
scrape_configs:
- job_name: incus
metrics_path: '/1.0/metrics'
scheme: 'https'
static_configs:
- targets: ['foo.example.com:8443']
tls_config:
ca_file: 'tls/server.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
# XXX: server_name is required if the target name
# is not covered by the certificate (not in the SAN list)
server_name: 'foo'
Note
The
scrape_intervalis assumed to be 15s by the Grafana Prometheus data source by default. If you decide to use a differentscrape_intervalvalue, you must change it in both the Prometheus configuration and the Grafana Prometheus data source configuration. Otherwise the Grafana$__rate_intervalvalue will be calculated incorrectly and possibly cause ano dataresponse in queries using it.The
server_namemust be specified if the Incus server certificate does not contain the same host name as used in thetargetslist. To verify this, openserver.crtand check the Subject Alternative Name (SAN) section.
For example, assume that server.crt has the following content:
~$ openssl x509 -noout -text -in /etc/prometheus/tls/server.crt... X509v3 Subject Alternative Name: DNS:foo, IP Address:127.0.0.1, IP Address:0:0:0:0:0:0:0:1...Since the Subject Alternative Name (SAN) list doesn’t include the host name provided in the targets list (foo.example.com), you must override the name used for comparison using the server_name directive.
Here is an example of a prometheus.yml configuration where multiple jobs are used to scrape the metrics of multiple Incus servers:
global:
# How frequently to scrape targets by default. The Prometheus default value is 1m.
scrape_interval: 15s
scrape_configs:
# abydos, langara and orilla are part of a single cluster (called `hdc` here)
# initially bootstrapped by abydos which is why all 3 targets
# share the same `ca_file` and `server_name`. That `ca_file` corresponds
# to the `/var/lib/incus/cluster.crt` file found on every member of
# the Incus cluster.
#
# Note: When the `project` param is provided, it overrides the `default` project
# and if not specified will pull all projects.
#
# Note: each member of the cluster only provide metrics for instances it runs locally
# this is why the `incus-hdc` cluster lists 3 targets
- job_name: "incus-hdc"
metrics_path: '/1.0/metrics'
params:
project: ['jdoe']
scheme: 'https'
static_configs:
- targets:
- 'abydos.hosts.example.net:8444'
- 'langara.hosts.example.net:8444'
- 'orilla.hosts.example.net:8444'
tls_config:
ca_file: 'tls/abydos.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
server_name: 'abydos'
# jupiter, mars and saturn are 3 standalone Incus servers.
# Note: only the `default` project is used on them, so it is not specified.
- job_name: "incus-jupiter"
metrics_path: '/1.0/metrics'
scheme: 'https'
static_configs:
- targets: ['jupiter.example.com:9101']
tls_config:
ca_file: 'tls/jupiter.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
server_name: 'jupiter'
- job_name: "incus-mars"
metrics_path: '/1.0/metrics'
scheme: 'https'
static_configs:
- targets: ['mars.example.com:9101']
tls_config:
ca_file: 'tls/mars.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
server_name: 'mars'
- job_name: "incus-saturn"
metrics_path: '/1.0/metrics'
scheme: 'https'
static_configs:
- targets: ['saturn.example.com:9101']
tls_config:
ca_file: 'tls/saturn.crt'
cert_file: 'tls/metrics.crt'
key_file: 'tls/metrics.key'
server_name: 'saturn'
After editing the configuration, restart Prometheus (for example, systemctl restart prometheus) to start scraping.
Set up a Grafana dashboard¶
To visualize the metrics data, set up Grafana. Incus provides a Grafana dashboard that is configured to display the Incus metrics scraped by Prometheus and log entries from Loki.
Note
The dashboard requires Grafana 8.4 or later with both Prometheus and Loki configured as data sources in Grafana.
It’s possible to add a placeholder Loki data source in Grafana to make it possible to import the dashboard in an environment that doesn’t have a fully set up Loki server. After import, remove the log sections at the bottom of the dashboard and then remove the placeholder Loki data source.
Incus logging to Loki is configured through the relevant server configuration.
See the Grafana documentation for instructions on installing and signing in:
Complete the following steps to import the Incus dashboard:
Configure Prometheus as a data source:
Go to Configuration > Data sources.
Click Add data source.
Select Prometheus.
In the URL field, enter
http://localhost:9090/if running Prometheus locally.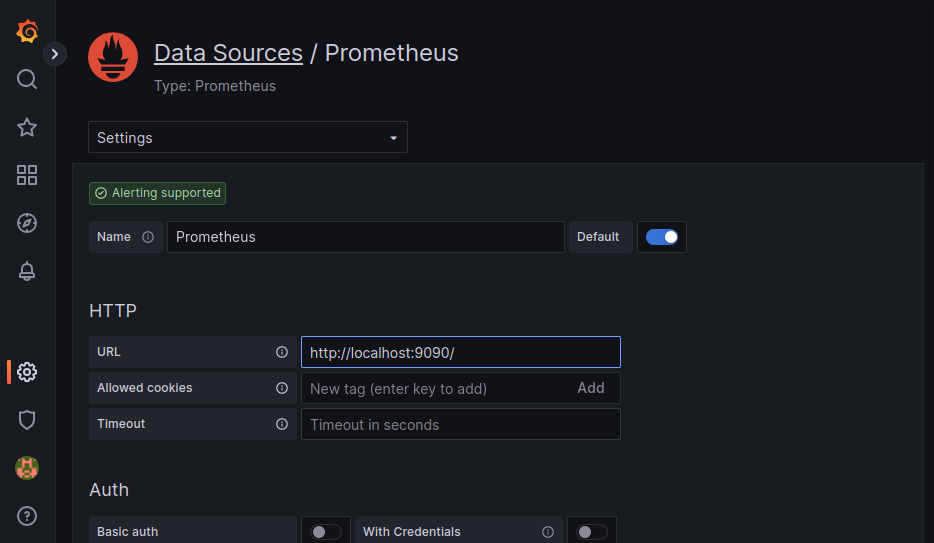
Keep the default configuration for the other fields and click Save & test.
Configure Loki as a data source:
Go to Configuration > Data sources.
Click Add data source.
Select Loki.
In the URL field, enter
http://localhost:3100/if running Loki locally.Keep the default configuration for the other fields and click Save & test.
Import the Incus dashboard:
Go to Dashboards > Browse.
Click New and select Import.
In the Import via grafana.com field, enter the dashboard ID
19727.
Click Load.
In the Incus drop-down menu, select the Prometheus and Loki data sources that you configured.
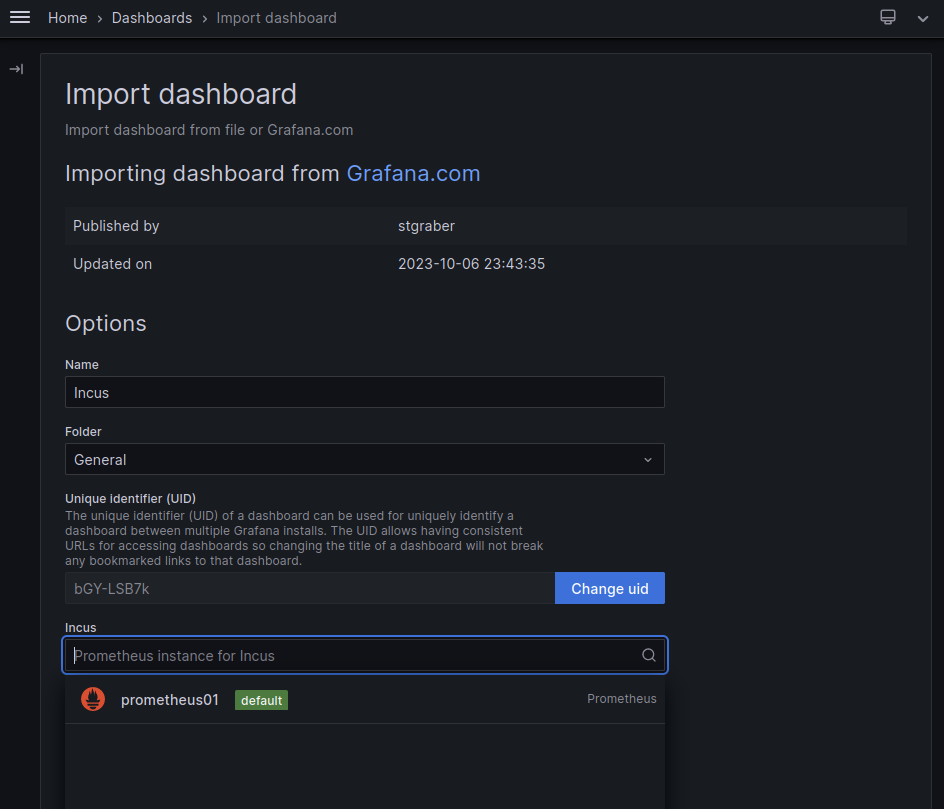
Click Import.
You should now see the Incus dashboard. You can select the project and filter by instances.
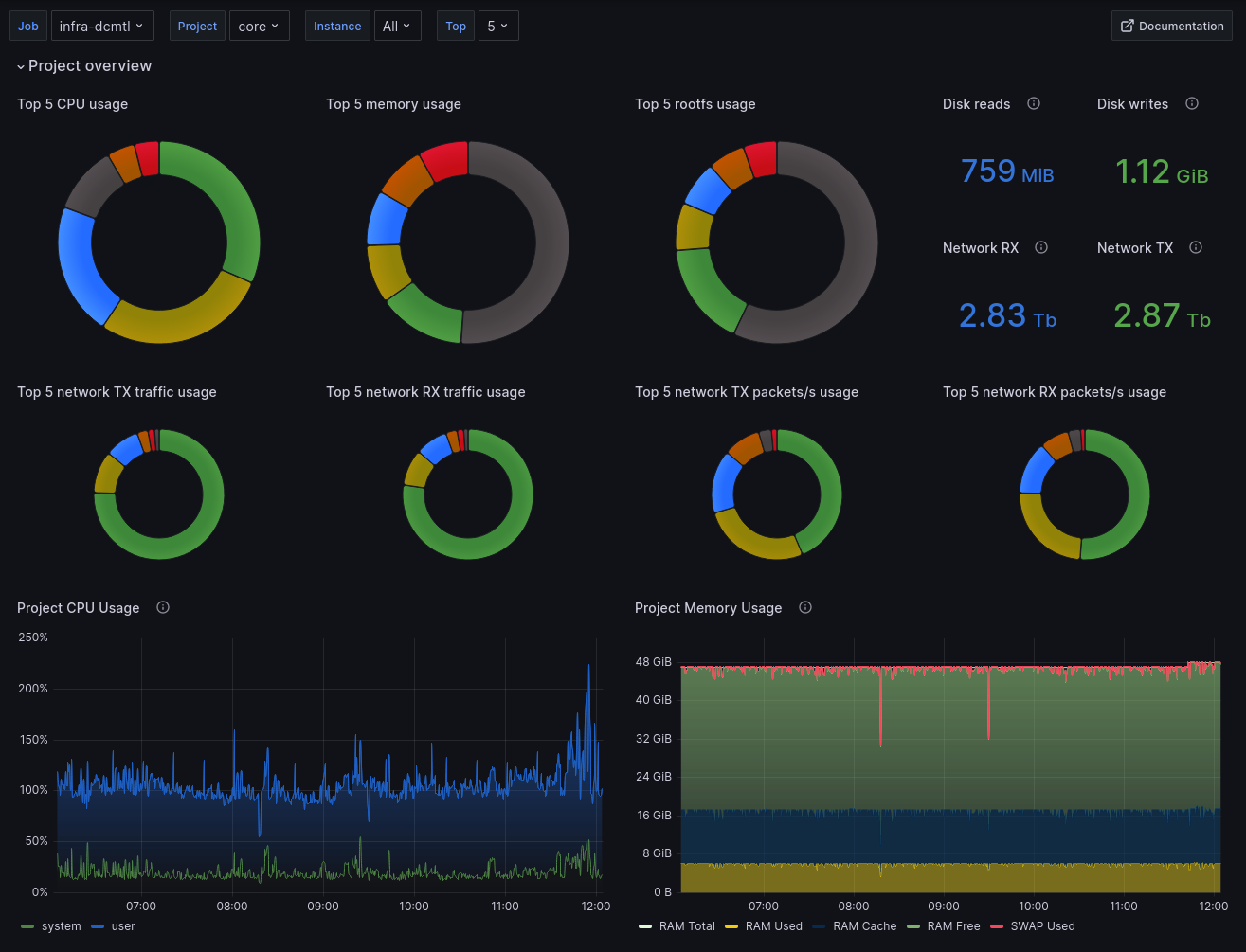
At the bottom of the page, you can see data for each instance.
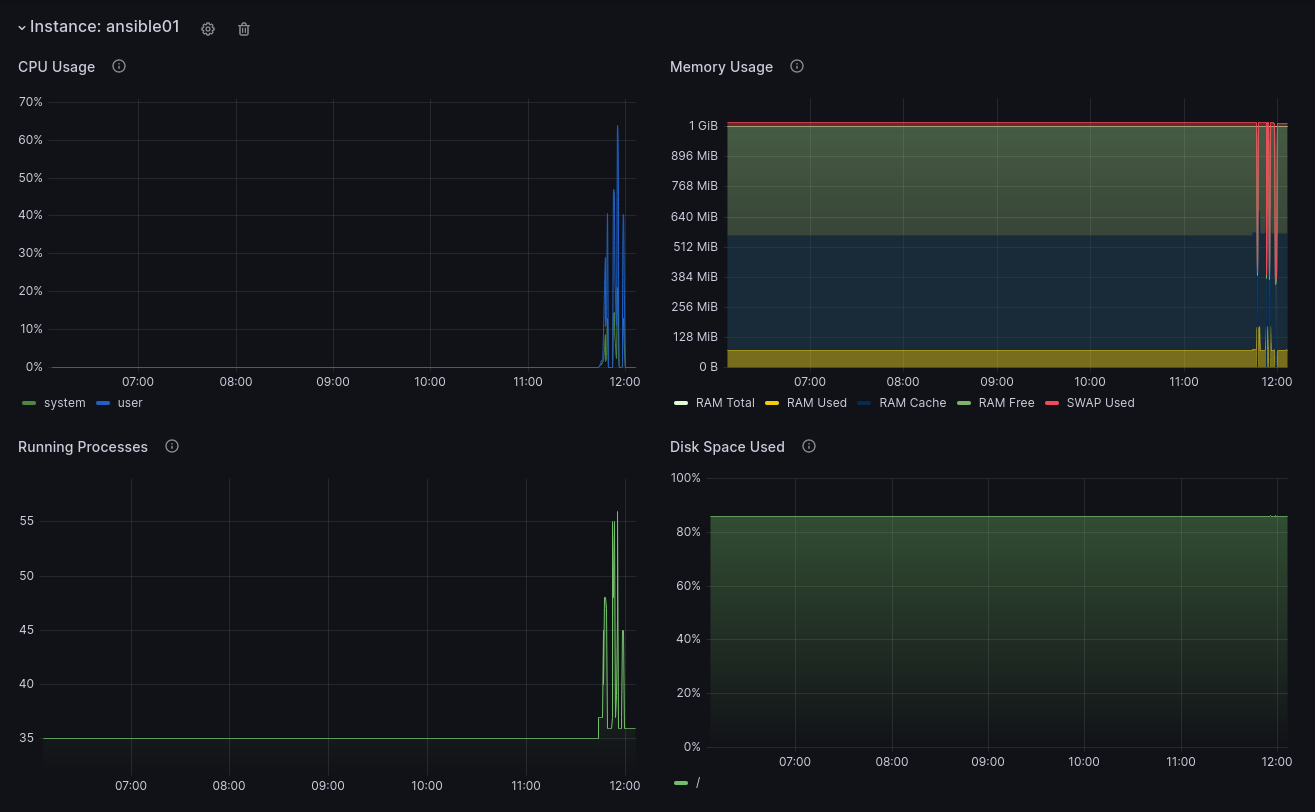
Note
For proper operation of the Loki part of the dashboard, you need to ensure that the instance field matches the Prometheus job name.
You can change the instance field through the logging.*.target.instance configuration key.